NIPS Workshop on Deep Learning and Unsupervised Learning, 2010
Piotr Mirowski, Marc’Aurelio Ranzato, Yann LeCun
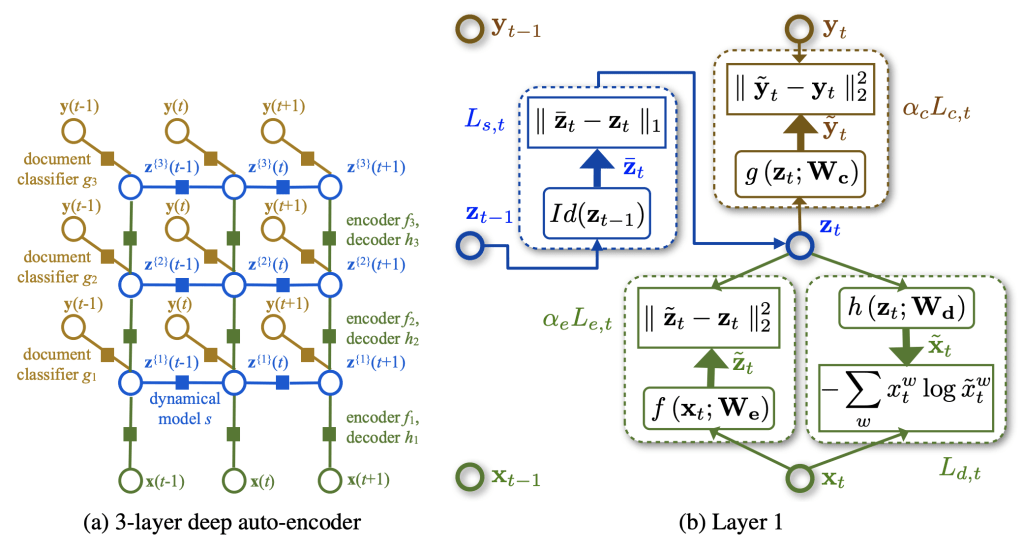
dependencies between latent variables. Right: Energy-based view of the first layer of the dynamic
auto-encoder.
We present a new algorithm for topic modeling, text classification and retrieval, tailored to sequences of time-stamped documents. Based on the auto-encoder architecture, our nonlinear multi-layer model is trained stage-wise to produce increasingly more compact representations of bags-of-words at the document or paragraph level, thus performing a semantic analysis. It also incorporates simple temporal dynamics on the latent representations, to take advantage of the inherent structure of sequences of documents, and can simultaneously perform a supervised classification or regression on document labels. Learning this model is done by maximizing the joint likelihood of the model, and we use an approximate gradient-based MAP inference. We demonstrate that by minimizing a weighted cross-entropy loss between histograms of word occurrences and their reconstruction, we directly minimize the topic-model perplexity, and show that our topic model obtains lower perplexity than Latent Dirichlet Allocation on the NIPS and State of the Union datasets. We illustrate how the dynamical constraints help the learning while enabling to visualize the topic trajectory. Finally, we demonstrate state-of-the-art information retrieval and classification results on the Reuters collection, as well as an application to volatility forecasting from financial news.
Paper link: Academia.edu
